- Instituto de Economía Aplicada Litoral (IECAL), Facultad de Ciencias Económicas, Universidad Nacional del Litoral.
- Instituto de Economía Aplicada Litoral (IECAL), Facultad de Ciencias Económicas, Universidad Nacional del Litoral.
RESUMEN
Palabras clave: Precios Alimentos; Supermercados, Santa Fe; Econometría Espacial
ABSTRACT
Keywords: food prices, supermarkets, Santa Fe, spatial econometrics
JEL Code: C21, L11, R32
INTRODUCCIÓN Y CONTEXTUALIZACIÓN DEL PROBLEMA
En Argentina el comportamiento de los precios en general, y el de los alimentos en particular, ha sido una preocupación permanente de los agentes de la economía, sobre todo del gobierno nacional debido a su impacto sobre la inflación y los indicadores macroeconómicos. Actualmente se discute el accionar del eslabón final de comercialización, donde el gobierno reconoce explícitamente la importancia de los grandes minoristas en la determinación de precios al consumidor implementando, a su vez, diferentes medidas para controlar el incremento de los mismos, incluyendo acuerdos como "precios cuidados" o “precios esenciales”, cuyo alcance es discutido.
En este sentido, la dispersión de precios es una regla más que una excepción y hay trabajos que analizan las causas y consecuencias de dicha existencia[2]. Una de las causas más mencionada es la existencia de imperfecta información (Stigler, 1961; Sorensen, 2000). Es un hecho que los consumidores no estén perfectamente informados y deban incurrir en costos de búsquedas en la toma de decisión de compra (Rhodes, 2015; Stahl, 1989).
Varian (1980) distingue entre dispersión de precios espacial y temporal. La primera ocurre cuando las firmas fijan precios en distintos momentos del tiempo, pero la posición de la firma en la distribución de precios general no cambia (se mantiene en la misma posición en el ranking de precios bajos/altos); en cambio, la segunda se observa cuando una misma firma ofrece precios de manera impredecible en el tiempo, variando el lugar en el ranking. A su vez, la fijación de precios por parte de la venta minorista puede estar influenciada por el nivel de competencia que un productor/vendedor tenga localmente, donde el consumidor vería reducido su costo de búsqueda (incrementado su utilidad) en la medida que exista mayor competencia y menor dispersión de precios.
En general, la problemática de la inflación argentina es abordada como un problema macro y monetario (Rappoport, 2011; Fernandez, 2017). Son escasos los estudios que analizan dicho problema desde la formación de precios y su relación con la comercialización en Argentina en un marco desagregado (Vicentin Masaro, Rossini y Chara, 2017). No se han encontrado trabajos que analicen empíricamente la posibilidad de que la ubicación geográfica y la cercanía entre competidores influencien las decisiones de fijación de precios. Es posible que la existencia de datos oficiales desagregados sea el motivo de la escasez de este tipo de análisis, aunque con el avance de la ciencia de datos se espera poder tener acceso a una mayor cantidad de información.
En un trabajo reciente, Vicentin Masaro, Rossini y Chara (2019) analizan la distribución de los precios de alimentos en la ciudad de Santa Fe en función de determinadas características del mercado y de los productos, con el objeto de estudiar la presencia de dispersión, comparando precios homogéneos por productos. Utilizando información de precios y mercado obtenidos de forma primaria, los autores no analizan ni prueban una posible correlación de precios, dejando abierta la posibilidad de realizar un análisis sobre correlaciones espaciales entre los precios. En este sentido, la información sobre fijación de precios correlacionada espacialmente resulta importante en varios frentes. Desde el punto de vista privado, los productores/vendedores podrían mejorar el diseño de estrategias comerciales y el proceso de toma de decisiones de precios y los consumidores podrían obtener una reducción de los costos de búsqueda en el proceso de compra de alimentos. En el ámbito público, se podría mejorar el diseño de políticas públicas sobre el control de precios y de la competencia para incrementar el bienestar de los consumidores.
Siguiendo dicha línea, en el presente trabajo se pretende detectar la existencia de dependencia espacial en la determinación de los precios minoristas de ciertos productos alimenticios para el caso de la ciudad de Santa Fe, teniendo en cuenta los supermercados insertos en la ciudad. Esto es, analizar posibles correlaciones en la fijación de precios entre minoristas con cercanía de ubicación, utilizando datos primarios y mediante la metodología empírica de Análisis Exploratorio Espacial de Datos (AEDE). El propósito final de dicho análisis es lograr, posteriormente, el modelado de los precios para cada producto entre los supermercados de Santa Fe, que mejor explique dichos precios en góndola.
MATERIALES Y MÉTODOS
Análisis exploratorio espacial, detección de valores atípicos y dependencia
En primer lugar, se realiza un análisis exploratorio de datos espaciales (AEDE) para conocer la distribución espacial de los precios. Mediante las herramientas gráficas, a saber, el mapa de percentiles y el de caja, se determina valores atípicos, i.e. detectar datos espacialmente atípicos (outliers).
Luego se determina la existencia de dependencia espacial global mediante el análisis en conjunto de las unidades que componen la muestra en total. De esta forma, se determina si las unidades se encuentran distribuidas aleatoria e independientemente o si, contrariamente, existe un patrón espacial determinado que agrupa las unidades. Siguiendo a Anselin y Bera (1998) en la definición de vecinos, sea ![]() la variable aleatoria de interés, entonces
la variable aleatoria de interés, entonces
![]() (1)
(1)
donde i y j corresponde a las ubicaciones en el espacio de la variable aleatoria (ubicaciones geográficas de las sucursales). Se utiliza la ecuación (1) para construir la interacción geográfica de los datos. Siendo n la cantidad de observaciones, existen [n(n-1)/2] auto-covarianzas espaciales. El número de parámetros a estimar excede a n, por lo que se impone una estructura sobre las relaciones de dependencia espacial siguiendo a LeSage y Pace (2009). Así, la definición de vecinos se encuentra expresada matemáticamente por la matriz de pesos cuadrada de orden n, donde cada unidad está representada mediante una fila y una columna. En cada fila, aquellos elementos que sean distintos de cero, estarán indicando vecindad (Herrera, 2015). Para cada punto geolocalizado, se define un polígono de influencia (polígonos Thiessen)[3] y se calcula la matriz de pesos por medio del criterio de contigüidad tipo reina.[4]
Definida la matriz de contactos o pesos, se utiliza el diagrama de dispersión de Moran,[5] el cual analiza la distribución de la variable ![]() en relación a la distribución de su retardo espacial
en relación a la distribución de su retardo espacial ![]() y distingue visualmente entre una dependencia espacial global positiva o negativa (Chasco Irigoyen, 2010). También posibilita la confirmación y/o detección de las observaciones atípicas halladas anteriormente. Por medio del ajuste por Mínimos Cuadrados Ordinarios (MCO) a través del origen de dicho diagrama, se obtiene el estadístico I de Moran que es el valor de la pendiente. Así, el mismo es
y distingue visualmente entre una dependencia espacial global positiva o negativa (Chasco Irigoyen, 2010). También posibilita la confirmación y/o detección de las observaciones atípicas halladas anteriormente. Por medio del ajuste por Mínimos Cuadrados Ordinarios (MCO) a través del origen de dicho diagrama, se obtiene el estadístico I de Moran que es el valor de la pendiente. Así, el mismo es
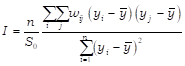 (2)
(2)
con ![]() , y 1 un vector
, y 1 un vector ![]() de unos y
de unos y ![]() es la media muestral. Un valor positivo del I indicaría dependencia espacial positiva de los datos I>(-1/n-1), mientras que un valor negativo denotaría correlación negativa I<(-1/n-1). Un I de Moran positivo y significativo indicaría agrupamiento o dependencia de valores en el espacio. De resultar negativo, podría indicar dependencia negativa o posible presencia de outliers o heterogeneidad espacial.
es la media muestral. Un valor positivo del I indicaría dependencia espacial positiva de los datos I>(-1/n-1), mientras que un valor negativo denotaría correlación negativa I<(-1/n-1). Un I de Moran positivo y significativo indicaría agrupamiento o dependencia de valores en el espacio. De resultar negativo, podría indicar dependencia negativa o posible presencia de outliers o heterogeneidad espacial.
En virtud de que el diagrama de Moran global no aporta datos sobre la significancia estadística dentro de cada cuadrante, no es capaz de detectar clústeres espaciales[6]. Para evaluar aglomeración (clústeres) en un área determinada, esto es, dependencia espacial para un subconjunto de los datos, se utiliza el Indicador Local de Moran (LISA).[7] De ser halladas, dichas formas de agrupación entre los datos muestreados, se está en presencia de dependencia espacial local o heterogeneidad espacial, esto es, líneas de discontinuidad geográfica (Anselin, 1999).
El estadístico Ii local de Moran calcula para cada sucursal i la existencia de agrupamiento espacial significativo entre valores vecinos similares. El I local de Moran es
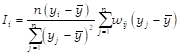 (3)
(3)
Donde wij es un elemento de la matriz de pesos espaciales W. La significancia del Ii puede contrarrestar sobre la base de la distribución normal, y siguiendo a Herrera (2015) se tienen en cuenta los clústeres espaciales que resultan significativos solo al p<0.001.
Análisis espacial de valores homogéneos
Considerando que, la diferencia en la característica observada ![]() puede deberse a otras covariables, es posible utilizar una estimación por MCO para modelar dicha variable respuesta. Dado los residuos de dicha estimación y luego de obtener los valores homogéneos, es posible calcular el estadístico I de Moran para, de este modo, detectar la correlación espacial de los valores homogéneos.
puede deberse a otras covariables, es posible utilizar una estimación por MCO para modelar dicha variable respuesta. Dado los residuos de dicha estimación y luego de obtener los valores homogéneos, es posible calcular el estadístico I de Moran para, de este modo, detectar la correlación espacial de los valores homogéneos.
El I de Moran funciona como prueba de especificación, evaluando la hipótesis nula de no existencia de dependencia espacial y sosteniendo que el modelo realiza un buen ajuste de los datos. Si dicha hipótesis es rechazada, un modelo determinado por MCO que no tenga en cuenta la correlación espacial, posee errores de especificación con problemas de eficiencia de los coeficientes.
Base de Datos e implementación
Se trabaja con información primaria tomada en supermercados de la ciudad de Santa Fe entre mayo del 2017 y mayo del 2018. En total, se tiene información de 44 sucursales, los cuales corresponden a once cadenas de supermercados de propiedad local, nacional e internacional. No se realiza una selección de sucursales, se monitorean las 44 sucursales correspondientes a todos los supermercados de la ciudad de Santa Fe, sin considerar mercados minoristas de barrio. Si bien originalmente, la información tiene una periodicidad quincenal, se promedian los precios de los productos considerados en el primer (1) y segundo semestre (2).
Los datos relevados corresponden a precios de productos alimenticios (y), a características físicas de las sucursales y a la ubicación geográfica de las mismas. Dichos productos corresponden a tres cortes de carne (nalga, picada común y asado), pan francés, leche fluida y huevos. Los dos primeros son medidos en $/kg; la leche fluida $ por sachet de litro y los huevos en $ por media docena en blíster de cartón. Todos los precios corresponden a pesos argentinos y fueron deflactados con base en agosto de 2018.
Con respecto a las características físicas de los supermercados se observan: la localización de la sucursal, la cantidad de sucursales de la cadena, si posee horario corrido, si posee estacionamiento, la cantidad de cajas, si tiene tarjeta de descuentos propia, si vende comida para llevar, si posee verdulería y el tamaño de la sucursal (en metros cuadrados). Además, se analiza la influencia de la cantidad de supermercados cercanos en un radio de 300 y 500 metros[8], no resultando significativas en ningún modelo.
Se utiliza el programa Stata 15 para el análisis no espacial de las muestras transversales de precios de alimentos. El resto del trabajo se realiza con los programas QGis y GeoDa. El primero para reproyectar la capa vectorial y el segundo, para realizar análisis exploratorios simple y espacial. Cabe mencionar que, siendo el presente trabajo una primera aproximación al análisis espacial, se definen a priori la forma de la matriz de pesos en función de los competidores más cercanos. En futuros se podría continuar hacia el análisis con datos de panel y explorar otras formas de representación de la matriz.
RESULTADOS
Análisis exploratorio de datos
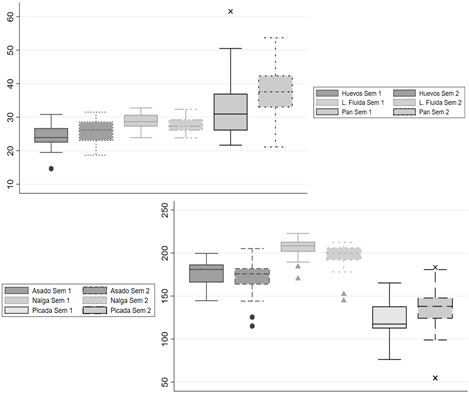
En la Figura 1 es posible observar que, dentro de los cortes de carne, los precios de la picada común son más dispersos que los otros dos cortes y, para el resto de los alimentos, el precio más variable es el del producto pan.[9]
Figura 1. Distribución de los precios por productos y semestres en la ciudad de Santa Fe.
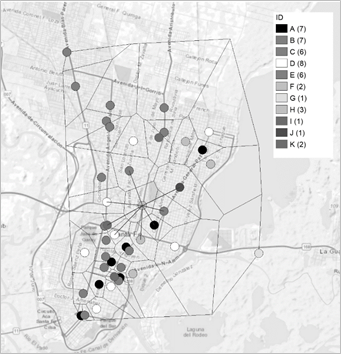
En la Figura 2 se muestra los polígonos de contigüidad de Thiessen a cada sucursal de supermercados de Santa Fe y la matriz de contigüidad definida tipo reina que arroja un arreglo espacial. Cada id representa a una cadena diferente y, en general, se observa que cada unidad tiene de vecinas sucursales de distintas cadenas de supermercados. Además, la observación con menos vecinos posee 2 unidades contiguas mientras que aquella con mayor cantidad de vecinos cuenta con 9 unidades; en promedio, cada sucursal tiene 5 observaciones vecinas. La cantidad de datos no nulos asciende a 11,26%,[10] con conectividad que se aproxima a una distribución normal (Anexo, Figura A1). De la Figura 2 (derecha) se observa como una sucursal ubicada en el centro de la ciudad consideraría como vecinas a 7 sucursales cercanas, las cuales pueden pertenecer a la misma cadena de supermercados como no.
Figura 2. Polígonos tipo Thiessen y gráfico de conectividad entre sucursales vecinas de la ciudad de Santa Fe.
De los mapas de percentiles que se muestran en las figuras 3 y 4 no es posible observar valores atípicos.
Análisis espacial y detección de valores atípicos
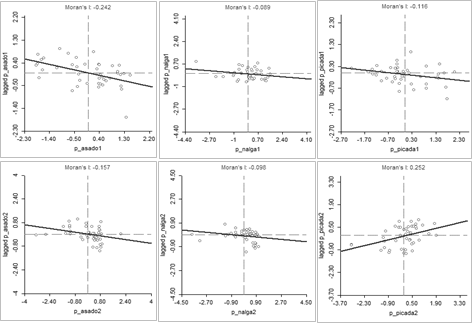
Los diagramas de Moran de los precios de los distintos cortes de carne en los 44 supermercados relevados en la ciudad de Santa Fe, muestran un comportamiento diferente según el corte específico. Si se analiza el corte élite (nalga), la nube de puntos se encuentra concentrada tanto en el primer como en el segundo semestre, donde la dependencia espacial sería negativa pero cuyo índice de Moran no resulta significativo (Tabla A2, Anexo). Los demás cortes, i.e. asado y picada común, son más baratos que la nalga, y las nubes de puntos resultan más dispersas. Mientras que el asado presenta leve dependencia espacial negativa en los dos períodos, ambos valores significativos, la picada tiene igual comportamiento solo en el primer semestre, aunque no significativo al 5%. Sin embargo, se puede observar una dependencia espacial positivaen el segundo semestre, significativa al 5 % (Figura 5). Los valores de probabilidad que permiten hacer la prueba de significancia se muestran en la Tabla A1 en Anexo.
Figura 3. Mapa de percentiles para los precios de los cortes de carnes en el semestre 1 (izq) y 2 (der).
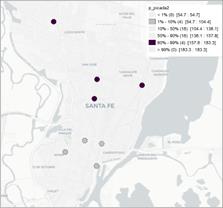
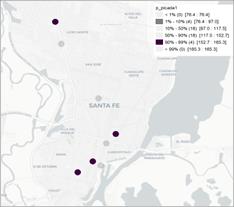
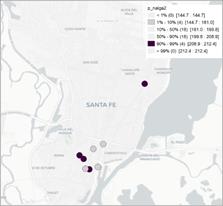
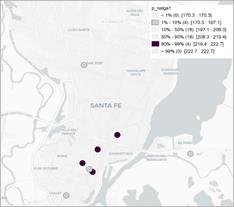
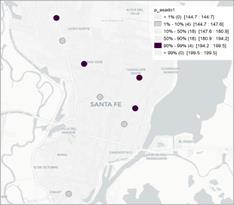
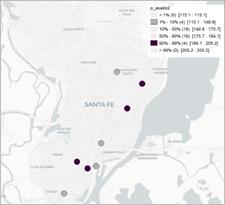
Figura 4. Mapa de caja para los precios del producto huevos, leche fluida y pan en el semestre 1 (izq) y 2 (der).
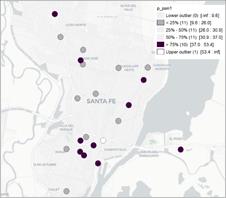
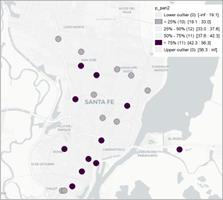
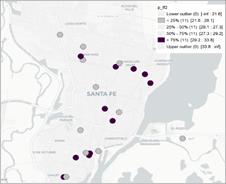
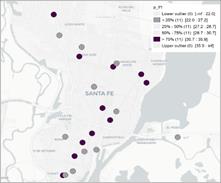
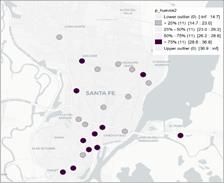
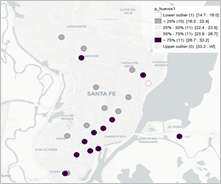
Figura 5. Diagramas de Moran e I de Moran para productos cárnicos en el semestre 1 (arriba) y 2 (abajo).
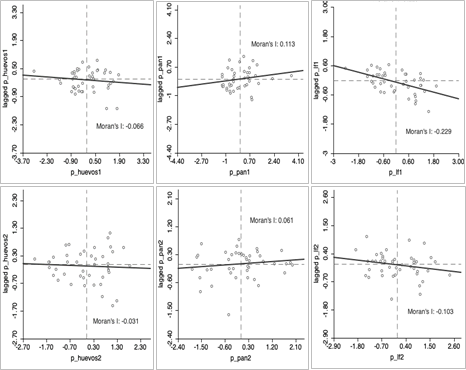
En el resto de los alimentos, es posible observar distintos patrones y significancias (Figura 6). Mientras el pan denota una dependencia espacial positiva en ambos semestres, pero no significativa, la leche fluida muestra un ajuste negativo, siendo solo significativo el valor del primer semestre y, los huevos tienen una distribución espacial aproximadamente nula en ambos semestres, no significativos.
Figura 6. Diagramas de Moran e I de Moran para huevos, pan y leche fluida en el semestre 1 (arriba) y semestre 2 (abajo).
Dependencia espacial local
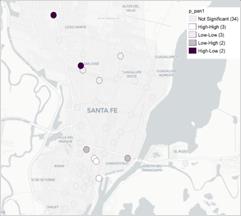
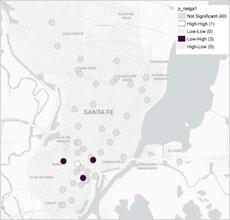
El local de Moran permite detectar clústeres espaciales, con un valor p < 0,001 solo para el caso de los productos nalga, huevos y pan (Figura 7). En el caso de la nalga, se halla un clúster espacial tanto en el precio del primer semestre como en el segundo. Dicha sucursal se caracteriza por ubicarse en el cuadrante Bajo-Alto del diagrama de Moran, esto es, teniendo precios bajos del producto nalga, la sucursal se rodea de supermercados con precios altos de dicho producto (en Figura A2 de Anexo es posible observar el mapa de significancia). Dicho clúster estaría indicando que en la muestra analizada existen zonas de la ciudad con comportamientos distintos a la tendencia general para el producto analizado.
Figura 7. Mapa Lisa de clúster para el producto nalga (semestre 1), huevos (semestre 2) y pan (semestre 1).
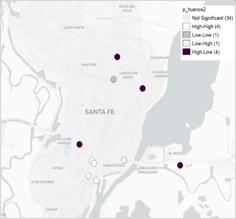
Se encuentra, además, un clúster en la distribución espacial de los precios del producto huevos en el segundo semestre. El mismo se ubica en el centro de la ciudad y está compuesto por una sucursal de la cadena El Túnel. Ésta posee precios altos para dicho producto y está rodeado de supermercados que mantienen también un precio alto, es decir, el clúster se ubica en el cuadrante Alto-Alto del diagrama de Moran (Figura 7).
No se encontraron agrupamientos significativos en los precios de la leche fluida. En cuanto a los precios del pan, se detecta un clúster significativo en el primer semestre, a saber, en el norte de la ciudad (Figura 7). Se trata de una sucursal caracterizada por presentar precios altos rodeada espacialmente por sucursales con precios inferiores, es decir, se ubica en el cuadrante Alto-Bajo del Diagrama de Moran.
Los distintos clústeres hallados demuestran, a su vez, que existe un comportamiento dispar en la dependencia espacial en los precios de los distintos productos, habría que pensar en la posibilidad de establecer una canasta para ver si en el agregado, dichas agrupaciones espaciales persisten.
Importancia espacial en la modelación
Se modelan los precios de los productos de cada semestre por MCO, dejando sólo aquellas variables independientes que resultan significativas. Para el caso de los cortes de carne, en la tabla 1 y 2 se muestran los resultados de los ajustes de los productos cárnicos y otros considerados en los cuales las variables independientes resultaron significativas.
Tabla 1. Parámetros estimados por MCO para los diferentes productos, y pruebas de especificación espacial.
Nota: prueba para un nivel de significancia de + <0.01, ** <0.05 y *<0.1. Los valores entre paréntesis son los errores estándares. Solo se calculan los modelos finales con las variables que resultaron significativas. En gris, las casillas excluidas del modelo por resultar no significativas.
Covariables |
Modelos: |
||||||
Asado. Semestre |
Nalga. Semestre |
Picada. Semestre |
|||||
1 |
2 |
1 |
2 |
1 |
2 |
||
Constante |
174.6+ |
164.5+ |
193.1+ |
176.2+ |
99.6+ |
117.8+ |
|
(5.322) |
(5.979) |
(3.584) |
(4.299) |
(8.759) |
(9.343) |
||
Cant. Sucursales |
2.2+ |
3.4+ |
2.1+ |
4.0+ |
5.0+ |
4.6+ |
|
(0.612) |
(0.777) |
(0.526) |
(0.713) |
(1.049) |
(1.505) |
||
Horario Corrido |
- |
- |
6.2* |
- |
- |
-19.5** |
|
(3.121) |
(8.173) |
||||||
Estacionamiento |
6.3* |
- |
- |
- |
- |
- |
|
(3.288) |
|||||||
Número de Cajas |
-1.4+ |
-0.9** |
- |
- |
-2.9** |
- |
|
(0.322) |
(0.398) |
|
(0.980) |
||||
Tarjeta Propia |
-23.9+ |
-22.0+ |
- |
-6.7* |
- |
-13.6* |
|
(2.949) |
(3.794) |
|
(3.563) |
(7.519) |
|||
Comidas para llevar |
12.9+ |
9.4** |
- |
- |
16.5** |
- |
|
(2.822) |
(3.516) |
|
(5.109) |
||||
Verdulería |
- |
- |
- |
- |
- |
- |
|
m2 |
- |
- |
- |
- |
0.01** |
- |
|
(0.002) |
|||||||
Pruebas de especificación |
|
|
|
|
|
|
|
I de Moran |
Estad |
-0.106 |
0.0794 |
-0.096 |
0.102 |
-0.050 |
0.3+ |
Valor |
-0.925 |
1.113 |
-0.729 |
1.299 |
-0.285 |
3.8009 |
|
LM (lag)
|
DF |
1 |
1 |
1 |
1 |
1 |
1 |
Valor |
0.781 |
0.200 |
0.820 |
0.076 |
1.255 |
7.274** |
|
Robust LM (lag) |
DF |
1 |
1 |
1 |
1 |
1 |
1 |
Valor |
0.026 |
0.100 |
0.007 |
4.309 |
1.559 |
0.103 |
|
LM (error) |
DF |
1 |
1 |
1 |
1 |
1 |
1 |
Valor |
1.154 |
0.648 |
0.940 |
1.059 |
0.259 |
10.46** |
|
Robust LM (error) |
DF |
1 |
1 |
1 |
1 |
1 |
1 |
Valor |
0.399 |
0.548 |
0.127 |
5.292 |
0.563 |
3.286 |
|
LM (SARIMA) |
DF |
2 |
2 |
2 |
2 |
2 |
2** |
Valor |
1.180 |
0.748 |
0.947 |
5.368 |
1.818 |
0.009 |
|
R2 |
0.759 |
0.613 |
0.310 |
0.507 |
0.455 |
0.301 |
|
n |
44 |
||||||
Tabla 2. Parámetros estimados por MCO para los diferentes productos, y pruebas de especificación espacial.
Nota: prueba para un nivel de significancia de + <0.01, ** <0.05 y *<0.1. Los valores entre paréntesis son los errores estándares. Solo se calculan los modelos finales con las variables que resultaron significativas. En gris, las casillas excluidas del modelo por resultar no significativas.
Covariables |
Modelos: |
|||
L. Fluida. Semestre |
Pan. Semestre 1 |
Pan. Semestre 1 |
||
1 |
2 |
|||
Constante |
28.2+ |
29.0+ |
43.6+ |
|
(0.958) |
(0.639) |
(4.991) |
||
Cant. Sucursales |
0.2755** |
- |
-0.8979** |
|
(0.105) |
(0.424) |
|||
Horario Corrido |
- |
- |
8.9378** |
|
(2.532) |
||||
Estacionamiento |
1.2678** |
1.0586* |
- |
|
(0.620) |
(0.600) |
|||
Número de Cajas |
-0.4917+ |
-0.4817+ |
- |
|
(0.105) |
(0.1018) |
|||
Tarjeta Propia |
- |
1.8608+ |
- |
|
(0.507) |
||||
Comidas para llevar |
2.1991+ |
- |
- |
|
(0.524) |
||||
Verdulería |
- |
- |
-8.7** |
|
(4.219) |
||||
m2 |
0.0005** |
0.0004** |
- |
|
(0.0001) |
(0.0001) |
|||
Pruebas de especificación |
|
|
|
|
I de Moran |
Estad |
-0.048 |
-0.084 |
0.02 |
Valor |
-0.259 |
-0.621 |
0.541 |
|
LM (lag)
|
DF |
1 |
1 |
1 |
Valor |
3.434* |
0.571 |
0.472 |
|
Robust LM (lag) |
DF |
1 |
1 |
1 |
Valor |
5.792** |
0.050 |
1.286 |
|
LM (error) |
DF |
1 |
1 |
1 |
Valor |
0.241 |
0.716 |
0.041 |
|
Robust LM (error) |
DF |
1* |
1 |
1 |
Valor |
2.599 |
0.160 |
0.855 |
|
LM (SARIMA) |
DF |
2** |
2 |
2 |
Valor |
6.033 |
0.731 |
1.327 |
|
R2 |
0.487 |
0.452 |
0.330 |
|
n |
44 |
|||
De todos los productos, sólo en el caso de la carne picada se debe tener en cuenta una especificación espacial. Como el I de Moran sólo permite detectar dependencia espacial pero no brinda información sobre la forma de ésta, se observan los test LM. Ya que los test LM (lag) y el LM (error) resultan significativos, brindan información sobre los modelos que podrían llegar a captar dicha correlación espacial. Se deja para trabajos futuros continuar en la modelización por medio de otros métodos de estimación, así como de especificación de la estructura de los errores.
CONCLUSIONES
En la Argentina el comportamiento de los precios de los alimentos no es un tema trivial y en reiteradas oportunidades se han tomado medidas para controlar este fenómeno. En este sentido, se comenzó a pensar en el efecto del supermercadismo y su liderazgo en la comercialización como un factor clave en la determinación de precios. Sin embargo, casi no hay estudios en Argentina que analicen la forma en que estos agentes interactúan en el proceso de formación de precios. La existencia de información asimétrica y el hecho de que los oferentes no se encuentren en ambientes completamente competitivos es un factor clave en la fijación de precios, y en este contexto, la localización y los competidores vecinos juegan un rol preponderante.
Así, el objetivo del presente trabajo ha sido detectar patrones espaciales en los precios minoristas de alimentos de la ciudad de Santa Fe que potencialmente puedan explicar las decisiones de fijación de precios de alimentos entre diferentes supermercados de la ciudad. Para ello, utilizando información primaria de precios de productos alimenticios tomada entre 2017 y 2018, se realiza un análisis exploratorio espacial para detectar si los valores altos o bajos en los precios de los productos ofertados al consumidor tienden a agruparse en el espacio.
Contrariamente a lo esperado, no se ha observado una fuerte dependencia espacial que se replica en todos los productos analizados. Al analizar dependencia espacial global en los alimentos, se encontró en asado y leche una dependencia espacial negativa significativa y positiva para la picada. En cuanto a la dependencia espacial local, se encontró un clúster espacial en los productos nalga, huevos y pan, demostrando heterogeneidad en la distribución de las sucursales. Las pruebas de dependencia espacial sólo indicaron que en picada común existen problemas de esa naturaleza.
Queda para futuros trabajos continuar con la complejización del modelo de detección de dependencia espacial, incorporando mayor cantidad de productos o realizando una canasta de bienes alimenticios, así como mejorando la modelización de los precios de los productos considerados.
ANEXOS
En la figura A1 se muestra el histograma de conectividad entre unidades consideradas vecinas según la matriz de pesos espaciales definida tipo reina, para los supermercados existentes en la ciudad de Santa Fe en 2017-2018.
Figura A1. Histograma de conectividad entre unidades vecinas.
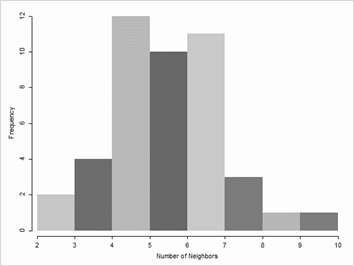
Tabla A1. Significancia del I de Moran para los precios de los alimentos relevados en Santa Fe, luego de 999 permutaciones.
Modelos |
I de Moran |
p-value |
Media |
Sd |
Asado_1 |
-0,2420 |
0,003 |
-0.0229 |
0.0957 |
Asado_2 |
-0,1575 |
0,053 |
-0,0235 |
0,0866 |
Nalga_1 |
-0,0886 |
0,245 |
-0,0221 |
0,0887 |
Nalga_2 |
-0,098 |
0,213 |
-0,0246 |
0,0863 |
Picada_1 |
-0,1159 |
0,174 |
-0,0258 |
0,0921 |
Picada_2 |
0,252 |
0,003 |
-0,0254 |
0,0892 |
Leche Fluida_1 |
-0,229 |
0,006 |
-0,0219 |
0,0904 |
Leche Fluida_2 |
-0,103 |
0,1910 |
-0,0226 |
0,0917 |
Huevos_1 |
-0.066 |
0.3350 |
-0.0228 |
0.0945 |
Huevos_2 |
-0.031 |
0.4880 |
-0.0196 |
0.0947 |
Pan_1 |
0,113 |
0,0720 |
-0,0251 |
0,0876 |
Pan_2 |
0,061 |
0,1730 |
-0,0233 |
0,0953 |
[1] Trabajo realizado en el marco del CAID 2016 titulado: “Demanda de alimentos y bebidas en Argentina. Sistemas con datos desagregados”. Director: Gustavo Rossini.
[2] Baye, Morgan y Scholten (2006) realizan una investigación detallada de la literatura teórica y empírica sobre la existencia de dispersiones en los precios.
[3] La técnica de interpolación de los polígonos Thiessen, permite particionar el plano elucídelo basándose en la distancia euclídea entre las unidades analizadas. Primeramente, se unen todos los puntos y se calcula las mediatrices de los segmentos, para luego diagramar los polígonos de acuerdo a las intersecciones de dichas mediatrices. Finalmente, el perímetro de los polígonos resulta equidistante a los puntos vecinos, indicando el área de influencia de una unidad en particular (Chasco Yrigoyen y Fernández-Ávilez, 2009).
[4] Siguiendo el criterio de contigüidad tipo reina, sea consideran vecinas aquellas unidades espaciales que tiene en común un borde y/o un vértice. Dicho criterio de vecindad resulta una analogía con el movimiento de la reina en el juego de ajedrez.
[5] El Diagrama de Moran es un diagrama de dispersión de una variable previamente estandarizada ![]() (eje X) y una variable espacialmente retardada de dicha variable
(eje X) y una variable espacialmente retardada de dicha variable ![]() en el eje Y. La dependencia espacial positiva/negativa se produce cuando una unidad adopta valores altos o bajos, rodeada de unidades con las mismas características/contrarias características.
en el eje Y. La dependencia espacial positiva/negativa se produce cuando una unidad adopta valores altos o bajos, rodeada de unidades con las mismas características/contrarias características.
[6] El diagrama de Moran resulta un buen indicador del grado de ajuste en la nube de puntos y logra brindar información sobre valores atípicos. Éstos podrían corresponderse con estructuras de dependencia espacial local, es decir, dependencia espacial dentro de un subconjunto de los datos o podrían ser, meramente puntos que no se ajustan bien (atípicos).
[7] Por sus siglas Local Indicator of Spatial Association.
[8] Se analiza la influencia de la cantidad (en número) de sucursales dentro de los buffers de 300 y 500 metros. Las sucursales dentro de cada buffer pueden diferir, asemejarse o incluso pertenecer a una misma cadena de supermercados.
[9] Consultar Vicentin Masaro, Rossini y Chara (2019) para un análisis exploratorio más detallado.
[10] Herrera (2015) recomienda tener menos del 15% para matrices no densas.
Referencias
- Anselin, L., Bera, A. K. (1998). Introduction to spatial econometrics. Handbook of applied economic statistics, 237.
- Baye, M. R., Morgan, J., Scholten, P. (2006). Information, Search, and Price Dispersion. Handbook on economics and information systems, 1, 323-375.
- Chasco, Yrigoyen, C. Fernández-Ávilez, G. (2009). Análisis de datos espacio-temporales para la economía y el geomarketing. Netbiblo.
- Chasco, Yrigoyen, C (2010). Detección de clusters y otras estructuras regionales y urbanas con técnicas de econometría espacial. Ciudad y territorio, estudios territoriales, 42(165-166), 497-512.
- Fernández, R. B. (2017). Dólar, inflación, déficit y la economía política Argentina (No. 609). Serie Documentos de Trabajo.
- Herrera Gómez, M., Mur Lacambra, J., Ruiz Marín, M. (2011). Which spatial weighting matrix? An approach for model selection (No. 37585). University Library of Munich, Germany.
- Herrera, M. (2015). Econometría espacial usando Stata. Breve guía aplicada para datos de corte transversal. Documentos de Trabajo del IELDE, 13.
- LeSage, J., Pace, R. K. (2009). Introduction to spatial econometrics. Chapman and Hall/CRC.
- Libman, E. (2018). Política monetaria y cambiaria asimétrica en países latinoamericanos que usan metas de inflación. Revista CEPAL.
- Rapoport, M. (2011). Una revisión histórica de la inflación argentina y de sus causas. En J.M Vázquez Blanco, S. Franchina (Comp.), Aportes de la Economía Política en el Bicentenario (pp. 135-165) Ed. Prometeo, Buenos Aires.
- Rhodes, A. (2015). Multiproduct Retailing. Review of Economic Studies, 82(1), 360- 390.
- Sengupta, A., Wiggins, S. N. (2012). Comparing price dispersion on and off the internet using airline transaction data. Review of Network Economics, 11(1).
- Sorensen, A. T. (2000). Equilibrium Price Dispersion in Retail Markets for Prescription Drugs. Journal of Political Economy, 108(4), 833-850.
- Stahl, D. O. (1989). Oligopolistic Pricing with Sequential Consumer Search. The American Economic Review, 79(4), 700-712.
- Stigler, G. J. (1961). The Economics of Information. The journal of political economy, 69(3), 213-225.
- Varian, H. R. (1980). A Model of Sales. The American Economic Review, 70(4), 651-659.
- Vicentin Masaro J., Rossini G. Chara, A. L. (2017). Dispersión de precios en alimentos: Un estudio preliminar en la ciudad de Santa Fe. Presentado en LII Reunión Anual de la Asociación Argentina de Economía Política, Bariloche.
- Vicentin Masaro J., Rossini G., Chara, A. L. (2019). Dispersión de precios en alimentos: Comparación del mercado físico. Presentado en XI Jornadas Interdisciplinarias de Estudios Agrarios y Agroindustriales, UBA, 5-8 noviembre.
Sobre la revista
ISSN 1666-5112 | eISSN 1669-1830
Cuadernos del CIMBAGE es una revista semestral, que incluye trabajos sobre aplicaciones de la lógica y la matemática a temas de gestión y economía.
DIRECTOR GENERAL
Javier I. García Fronti
CODIRECTORES
Alberto H. Landro
María José Bianco
María José Fernández
SECRETARIA DE REDACCIÓN
Raquel Soto